Analytics Features
A deep dive into the various analytics features offered by Analytics Studio
Overview
- Metrics
- Voice Metrics
- Messaging Metrics
- Verb Noun Pairs
- Entity Detection & Redaction
- PCI
- SSN
- Numbers
- Organizations
- Persons
- Keywords and Topics
- Number Formatting
- Resolution Model
Voice Metrics
Analytics Studio enables you to apply to a recording predefined algorithms that compute metrics useful for tracking the quality of the conversation in the recording. Each metric is applied to the transcription results, uses the word timing and words themselves and the numeric results for each metric are provided with the json output
- Overtalk Metrics
- Overtalk Incidents - the number of times that the agent and caller talked at the same time, expressed as an integer from zero to n.
- Agent Overtalk Incidents - the number of times that the agent began talking while the caller was already talking, expressed as an integer from zero to n.
- Caller Overtalk Incidents - the number of times that the caller began talking while the agent was already talking, expressed as an integer from zero to n.
- Overtalk Ratio - The percentage of the total call duration where the agent and caller talked at the same time, expressed as a number from 0 to 1 with .01 resolution, with 0.1 corresponding to overtalk for 10% of the call.
- Agent Overtalk Ratio - The percentage of the call where the agent and caller talked at the same time, and where the caller began talking first (e.g. the agent talked over the caller) expressed as a number from 0 to 1 with .01 resolution.
- Caller overtalk Ratio - The percentage of the call where the agent and caller talked at the same time, and where the agent began talking first, expressed as a number from 0 to 1 with .01 resolution
- Talk Time and Rate Metrics
- Agent Talk Ratio - the percentage of non-silence time that the agent was talking, expressed as a number from 0 to 1 with .01 resolution. In narrative form, this answers the question "What percentage of the talking did my agent do compared to the caller?"
- Caller Talk Ratio - the percentage of non-silence time that the caller was talking, expressed as a number from 0 to 1 with .01 resolution.
- Silence Ratio - the percentage of time where neither the caller nor the agent were talking, expressed as a number from 0 to 1 with .01 resolution.
- Silence Incidents - the number of times that neither the agent nor the caller were talking, where the duration was >4 seconds, expressed as an integer from zero to n.
- Agent Talk Rate - the average rate of speech for the agent over the entire call, with times when the other part is talking and significant pauses removed, expressed as word per minute (WPM) as an integer from zero to n.
- Caller Talk Rate - the average rate of speech for the agent over the entire call, with times when the other part is talking and significant pauses removed, expressed as word per minute (WPM) as an integer from zero to n.
- Agent to Caller Talk Rate Ratio - a measure of agent talk rate compared to the caller talk rate, expressed as ratio; see the definitions doc for the updated definition.
- Agent intra-call change in talk rate - a measure of the talk rate for the agent, as measured above, from the first 1/3 of the call compared to the rate from the last 1/3 of the call, expressed as a number from zero to positive n, where 1.0 represents no change on talk rate and .3 represents a 70% decrease in talk rate.
- Caller intra-call change in talk rate - a measure of the talk rate for the caller, as measured above, from the first 1/3 of the call compared to the rate from the last 1/3 of the call, expressed as a number from zero to positive n, where 1.0 represents no change in talk rate and .3 represents a 70% decrease in talk rate.
- Agent Longest Talk Streak - the total time for the longest streak of an agent talking, expressed in seconds. A streak starts with the first word spoken by the agent at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Caller Longest Talk Streak - the total time for the longest streak of a caller talking, expressed in seconds. A streak starts with the first word spoken by the caller at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Longest Talk Streak - the total time for the longest streak of an agent or caller talking, expressed in seconds. A streak starts with the first word spoken by any of the speakers at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Agent Average Talk Streak - the average time for all streaks of an agent talking, expressed in seconds. A streak starts with the first word spoken by the caller at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Caller Average Talk Streak - the average time for all streaks of a caller talking, expressed in seconds. A streak starts with the first word spoken by the caller at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Average Talk Streak - the average time for all streaks of both an agent and a caller talking, expressed in seconds. A streak starts with the first word spoken by any of the speakers at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Agent Median Talk Streak - the median of all streaks of an agent talking, expressed in seconds. A streak starts with the first word spoken by the caller at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Caller Median Talk Streak - the median of all streaks of a caller talking, expressed in seconds. A streak starts with the first word spoken by the caller at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Median Talk Streak - the median of all streaks of both an agent and a caller talking, expressed in seconds. A streak starts with the first word spoken by any of the speakers at the beginning of a call or the next word spoken after a pause of 3 seconds or more. It ends with a pause of 3 seconds or more or the end of the call or when the other party starts speaking simultaneously, but only if they speak for longer than 2 seconds.
- Longest silence streak - the longest interval when nobody is talking.
- Talk Style, Tone, and Volume Metrics
- Agent Relative Voice Volume/Energy - a measure of how loudly/aggressively/energetically an agent speaks. It is the ratio of the average volume of agent’s words to a fixed avg. volume of a good agent. (The average volume of a good agent was computed from some reference calls where the agents were ranked as good and bad).
- Caller Relative Voice Volume/Energy - a measure of how loudly/aggressively/energetically a caller speaks. See above.
- Agent intra-call change in relative voice volume/energy - a measure of the agent's relative voice volume/energy (see above) in the first 1/3 of the call compared to that of the last 1/3 of the call, expressed as a number from zero to positive n, where 1.0 represents no change in volume and .3 represents a 70% decrease in volume.
- Caller intra-call change in relative voice volume/energy - a measure of the caller's relative voice volume/energy (see above) in the first 1/3 of the call compared to that of the last 1/3 of the call, expressed as a number from zero to positive n, where 1.0 represents no change in volume and .3 represents a 70% decrease in volume.
- Agent intra-call change in pitch - a measure of how the agent's pitch changed during the call. The hypothesis is that an agent whose pitch increased during the call likely represented an increase in conflict/tension.
- Caller intra-call change in pitch - a measure of how the caller's pitch changed during the call.
- Agent Understandability Score - building on Bruce's notion that a bad transcript tells us something about the speaker, is there a way to roughly measure how good we think our transcript is, and to produce a score that attempts - if even roughly - to measure how understandable the agent is? Even if this is really rough, it would make a good addition to a POC set of metrics.
- Caller Understandability Score - building on Bruce's notion that a bad transcript tells us something about the speaker, is there a way to roughly measure how good we think our transcript is, and to produce a score that attempts - if even roughly - to measure how understandable the agent is? Even if this is really rough, it would make a good addition to a POC set of metrics.
- Agent Voice Dynamism Score - a measure of how dynamic (varied and interesting) the agent's voice appears. It is computed as the standard deviation from the average volume for the agent's words.
- Caller Voice Dynamism Score - a measure of how dynamic (varied and interesting) the caller's voice appears. It is computed as the standard deviation from the average volume for the caller's words.
- Agent Vocabulary - the number of unique words spoken by the agent during the call.
- Caller Vocabulary - the number of unique words spoken by the caller during the call.
- Sentiment Metrics
- Call Sentiment - a simple whole-call sentiment metric. A real number between -1 and 1. If this number is close to -1 then the sentiment is negative. If it is close to 1 then its positive. And if it is close to 0 then neutral.
- Agent Sentiment - the above whole-call metrics measuring only the agent
- Caller Sentiment - the above whole-call metric measuring only the caller
- Start Sentiment - sentiment metric for the first one-third of the call. A real number between -1 and +1, same as call sentiment metric but computed only for the start 1/3rd of the call duration.
- End Sentiment - sentiment metric for the last one-third of the call. A real number between -1 and +1, same as call sentiment metric but computed only for the end 1/3rd of the call duration.
- Agent Start Sentiment - see above
- Agent End Sentiment - see above
- Caller Start Sentiment - see above
- Caller End Sentiment - see above
- Call Change in Sentiment - the change in sentiment from the first 1/3 of the call compared to the last 1/3 of the call, expressed as a real number between -2 to +2. It is the difference between the sentiment scores of end and start segments. For example, call-change-in-sentiment = end-sentiment - start-sentiment
- Agent Intra-call Change in Sentiment - see above
- Caller Intra-call Change in Sentiment - see above
Messaging Metrics
LivePerson offers brands ready-made dashboards reflecting historic data drawn from their LivePerson Conversational Cloud account activity. These dashboards allow brands to monitor and optimize contact center operations, increase conversions through campaigns and enact data-driven decisions.
- Overall Sentiment
- Change in Sentiment A score that subtracts the End-sentiment from the Start-sentiment. The range is -2 to 2 with a -2 for a call that started very positive but ended very negative, 0 for a call that did not change in sentiment and 2 for a call that started very negative but ended very positive.
- Overall Sentiment
- Start Sentiment - sentiment metric for the first one-third of the call. A real number between -1 and +1, same as the call sentiment metric but computed only for the start 1/3rd of the call duration.
- End Sentiment - sentiment metric for the last one-third of the call. A real number between -1 and +1, same as call sentiment metric but computed only for the end 1/3rd of the call duration.
- Messaging Response Time
- Max First Response Time - The Maximum Time Taken To First Respond To The Consumer For New Conversations Or Transferred Conversations. For Transferred Conversations The Time Is Measured From The Time Of Transfer To The Time Of Agent Response. Attributed To The Time The Conversion Was Assigned To The Agent (Agent Segment Start Time).
- Average Response Time - The Avg Max Response Time Taken By The Bot To Respond To A Consumer Message From Bot Assignment. Based On Avg. Time To Response From Agent Assignment For Bot Agents.
- Max Response Time - The Avg Max Response Time Taken By The Bot To Respond To A Consumer Message. Time Is Measured From The First Of Consecutive Messages Sent By A Consumer If A Conversation Just Started Or From The Start Of The Conversation If There Is No Message From Consumer. Based On Avg. Wait Time For First Agent Response
- Total Wait Time - The Time On Average A Consumer Who Messaged The Brand For The First Time Waits For A Response From The Brand. Measured From The Time The First Message Was Sent By The Consumer To The First Response Provided By An Agent In The Conversation.
- Transfer Count - Number Of Transfers. The Transfer Is Attributed To The Skill From Which The Transfer Was Initiated And Agent Who Initiated The Transfer
- Message Count -
- Total No. Of Messages Sent By Bot - Total Number Of Messages Sent By The Bots.
- Total No. Of Messages Sent By Consumer - Number Of Messages Sent By Consumers Including Unassigned Conversations.
- Total No. Of Messages Sent By Consumer To Agent - Number Of Messages Sent By Consumers While An Agent Was Assigned To The Conversation. This Kpi Is Not Assigned To A Specific Agent
- Core Metrics
- # Agent Responses - Count of all agent responses.
- # Agent Volume - Count of all conversations handed by a human agent.
- Volume - Distinct count of all conversations.
- Agent First Response Time - Total elapsed time from the beginning of a conversation to when an agent responds. I.e. The amount of time the agent takes to respond, for the very first time.
- Agent Quality Score - Overall quality score of the agent based on various scoring categories.
- CSAT Avg - Overall average of the CSAT score for all conversations
- CSAT Score - A score for conversations where the consumer satisfaction score is greater than or equal to 4
- DAR - Daily Active Relations. You may think of this as daily active users/customers who have interacted with the bot or human agent.
- Duration - Average Duration of all conversations.
- MCS AVG - Average of MCS scores from all conversations.
- NPS AVG - Average of NPS scores from all conversations.
- NPS Score - Count of conversations where the average Net Promoter Score was greater than or equal to 9.
- Precision Metrics
- # Assigned Volume - Count of conversations that were assigned a human agent.
- # Bot Volume - Count of conversations that were handled by a bot
- # Handled Volume - Count of conversations that were handled by either a human agent or a bot.
- # Survey Responses - Count of conversations where the customer responded to the survey.
- % >5M First Response - Percentage of conversations where the agent took more than 5 minutes for their very first response to the customer.
- % Agent Volume - Of all conversations that took place, this is the percentage of conversations handled entirely by a human agent.
- % Bot Volume - Of all conversations that took place, this is the percentage of conversations handled entirely by a bot.
- % Contained - Percentage of conversations that were handled entirely by the bot excluding out of office hours.
- % Fallback - Percentage of conversations where the system did not understand the customer's response and hence a fallback message was triggered.
- % First Timer - Percentage of conversations the customer is initiating an interaction for the first time.
- % Ghost - If an agent is assigned to a conversation but the agent does not respond at all.
- % Intentful Conversation - The percent of conversations that have an intent that is recognised by the analytics studio engine.
- % OOH - Percent of conversations that were initiated during Out of Office Hours or when an agent was not available.
- % RCR - 1 Day / 3 Days / 7 Days / 30 Days / 35 Days / 70 Days - The percent of conversation where the user/customer initiated an interaction, left and then returned to the conversation after 1 day / 3 days / 7 days / 30 days / 35 days or 70 days.
- % Survey Responses - Percentage of conversations where the customer responded to the (CSAT) survey questions.
- % Timeout - Conversations marked as "Timeout" are the number of conversations with the close reason: Timeout. So "%Timeout" will be the percentage of such conversation against the total number of conversations.
- % Transfers - The percentage of conversations that are transferred one or more times out of the volume.
- AOV - Average Order Value. This is the total sales amount divided by total sales volume.
- Agent Avg Response Time - Average time taken for an agent to respond to a customer message.
- Agent First Response Time - Amount of time taken for an Agent response from the first customer message. Time is measured from the first of consecutive messages sent by a consumer.
- Agent Max Response Time - Maximum time taken for an agent to respond to customer.
- Agent Responses per Convo - Average number of Agent Responses out of the total volume.
- Agent Responses per Minute - Average number of Agent Responses within a minute.
- Bot Avg Response Time - Average amount of time taken by Bot to respond to a customer message.
- Conversion Rate - Count of conversations that resulted in a sale divided by total count of conversations. I.E. Sales quantity divided by total count of conversations.
- Sales Amount - Total value of sales made across all conversations.
- Sales Quantity - Count of conversations that resulted in a sale.
- Difference in Volume - Difference in Volume, given a date. The user has to select a date based on which the prior Volume and current Volume is calculated.
- Difference in CSAT - Difference in CSAT score, given a date. The user has to select a date based on which the prior CSAT and current CSAT is calculated.
- Agent Messages per Convo - Average number of messages sent by Agent, per conversation.
Meaningful Conversation Score(MCS)
MCS is an automatic, unbiased method to measure the relationship between consumers and brands. The MCS evaluates and measures the overall customer relationship, solving a major issue inherent in other customer satisfaction measurements.
MCS is based on a detected sentiment and is calculated using a specific formula - further explanation of this can be found below. The MCS range is between -100 to 100.
Calculating MCS
Each message in a conversation is given a score dependent on the sentiment expressed in the message: positive, neutral or negative. The more positive the message, the higher the score; the more negative, the lower the score.
The MCS aggregates the sentiment scores up to each point in the conversation, taking into account the emotional consumer context for each message. Within the aggregation, positive messages are weighted less than negative messages, at a ratio of 1:2 between positive and negative. This is indicated in the formula below by the ⅓ for positive messages and the ⅔ for negative messages.
The more recent the message, the greater the effect it will have on the total score. Some negative impact of a score remains regardless of the time that has passed, i.e. if negative emotion has been detected, it will linger through the entire conversation to some extent.
The dynamic changes to the MCS can be tracked in the Web Messaging API.
MCS Metrics
There are 3 types of MCS scores (Agent, Caller(Customer) and Call), available both for speech(voice/calls) as well as messaging.
MCS being is a singular score for measuring the sentiment of the entire conversation rather than per turn, is a decimal number between -100 and 100 to denote the overall sentiment of an interaction between agent and customer (Voice as well as messaging) as a whole.
A score below 0 (-100 to 0) denotes a negative sentiment whereas a score above 0 (1 to 100) denotes a positive sentiment.
Agent MCS - Denotes the Sentiment score assigned to the agent attending to the call/messaging interaction.
Caller MCS - The Sentiment score assigned against the customer.
Call MCS - The overall MCS assigned to the interaction as a whole taking both sides into consideration.
Intents
The vision of the intent-driven business is to fundamentally change how brands understand and act on what their consumers want and need—not through proxies like website click patterns—but with consumers’ own intents. LivePerson’s Intent Manager allows you to do this. And you can get up and running very quickly with prebuilt domains.
Intent Manager’s proprietary natural language understanding (NLU) engine extracts consumer intents at every turn of the conversation. It comes pre-configured for a variety of industries, to automatically understand a high percentage of consumer intents entirely out of the box. It offers flexibility for data scientists, content creators, and non-technical employees to fine-tune or configure custom intents from a simple interface.
Why Use Intents?
Intents are meant for when you need a more flexible approach to utterance matching than using patterns. With patterns, there must be an exact match between the consumer's utterance and the defined pattern. This means that alternative expressions (synonyms, phrasings, and formats) are missed.
Verb-Noun Pairs
Noun-Verb Pairs enables analysts and business users to organically discover topics of discussion within calls, email, chat, survey, and social media without having to create categories. POS, specifically noun-verbs-pairs, pulls out the nouns and each noun's associated verb from each text sentence. The nouns are then paired with their associated verbs together from a call, set of calls, or text files to visualize the groupings of nouns (by count) and their associated verbs (by count) for each noun.
"Neg" and "Noun-neg" are optional fields. When present, they indicate a negative modifier for the verb or noun, respectively.
When the Verb-Noun Pairs feature is combined with Sentiment by Turn, nouns and verbs pairings will be able to carry a sentiment score and display sentiment by noun and verb cluster so the user can understand the topical drivers of positive and negative sentiment.
Here are some examples of Verb-Noun Pairs from a dummy transcript:
- Calling team
- Need help with my account
- I do not have a question
- The stupid internet doesn"t work
- My internet is not working
- My internet never works
- They provide no justification
- Do they like our service
Entity Detection & Redaction
Analytics Studio has a flexible detection and redaction solution, powered by predictive models built in-house by the data science team. Fundamentally we detect the region of a conversation where an event was discussed (PCI, SSN, All Numbers, etc) and then we offer 3 options for the level of redaction needed:
Numbers Only
This would redact only numbers transcribed within the region like “4” or “four”.
Probably Numbers
This would redact numbers (“4”, “Four”) and probable numbers like synonyms to numbers like “for” or “ate” that are present within the region.
Entire Region
This redacts the entire region of the call where we detected this event was discussed.
Analytics Studio has out-of-the-box models to detect certain events such as PCI, SSN, All Numbers (commonly referred to as number blaster). For certain use cases where there are other similar events occurring, we may recommend training a custom model for a customer.
Detectors are trained on voice data but work on both speech and messaging data.
Entity Extraction
Analytics Studio Entity Extraction locates named entities mentioned in an audio file, then classifies them into pre-defined categories such as person names, organizations, locations, time expressions, quantities, and monetary values.
Available entities include "location", "person", "organization", "money", "number", "phone", "time", and "date".
Here is an example of possible entities extracted from a dummy transcript:
{
[{
"four one five eight zero nine nine",
"phone",
"4158099",
32582,
36183
"Aisha",
"person",
2160,
2490
"San Francisco",
"location",
2760,
3030
"VoiceBase",
"organization",
43075,
43705
"money",
"$240.00",
"two hundred forty",
55549,
57779,
{
240,
0
"time",
"o'clock",
168519,
168989
Redaction
Analytics Studio enables automated detection and redaction of credit card numbers, social security numbers and other sensitive information.
VoiceBase Engine has Entities as an automated way to tag the transcript with parts of speech or specific types of text; "location", "person", "organization", "money", "number", "phone", "time", and "date".
There are use cases for both, redacting all “organizations” as well as only redact when “organization” = “Example Company”.
Keywords & Topics
Analytics Studio can discover the keywords, key phrases, and topics in your recording using a processing known as semantic indexing. The results are known as "semantic knowledge discovery" and it includes keywords and topics. These keywords and topics are discovered automatically (for languages where the feature is supported).
Analytics Studio also supports keyword and key phrase spotting. You can define groups of keywords or key phrases, which are flagged when they are spotted in the recording.
Here's an example of keywords & topics detected & relevant metrics from a dummy transcript.
// Example 1 - Keywords
"subscription",
0.17,
: [
: "caller",
: [
"s": 34480, "exact": "subscription" },
"s": 57340, "exact": "membership" }
: "agent",
: [
"s": 40010, "exact": "subscription" }
"Solar energy",
[ ],
0.004,
[
"solar power",
0.17,
: [
: "caller",
: [
"s": 34480, "exact": "solar power" },
"s": 57340, "exact": "solar energy" }
: "agent",
: [
"s": 40010, "exact": "solar power" }
In the above example, the keyword "subscription" was spoken by the caller around 34 and 57 seconds into the recording, and by the agent around 40 seconds into the recording.
Topics are reported by grouping a set of keywords that relate to each other.
Number Formatting
The Number Formatting feature transcribes numbers in digit form, that is, "1" rather than "one". Number formatting is enabled by default.
For example, with number formatting disabled, a transcript might read:
"Agent: The total of your bill comes to one hundred thirty eight dollars and sixty five cents"
When number formatting is enabled it will read:
"Agent: The total of your bill comes to $138.65"
Additionally, Analytics Studio can detect phone numbers and format them into a US phone number format within the transcript. Note that, Number Formatting happens only for speech conversations. For text conversations, the numbers formatting is preserved from the user inputs.
Resolution Model
The resolution model is a binary classifier that indicates whether a conversation between a consumer and agent has been resolved or not (to the consumer’s satisfaction). More specifically, at the end of the conversation, have all of the consumer’s primary intents been met or are there still open intents that the brand has not yet resolved?
Since the resolution model is implemented as a classifier, it is added to the ‘Jobs Queue’ page. The user experience will be similar to running a categorisation job

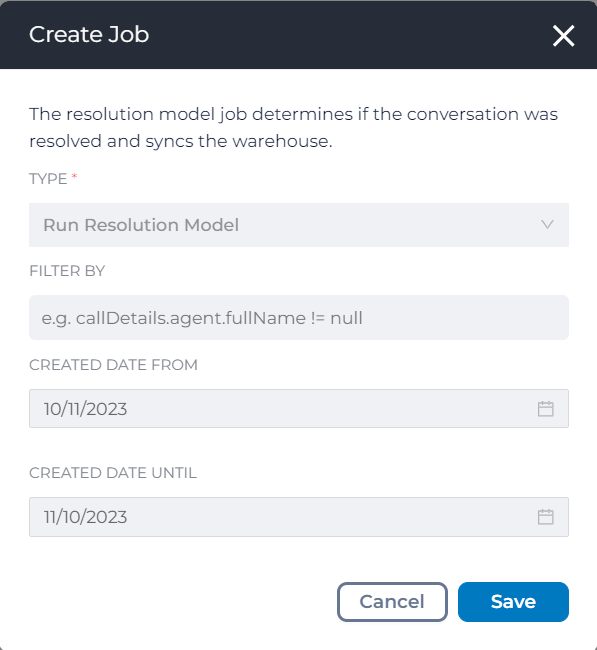
resolution_model_job_queue
Note: Classifier needs to be turned on on content (call) level in the account settings before we run the Resolution Model job.

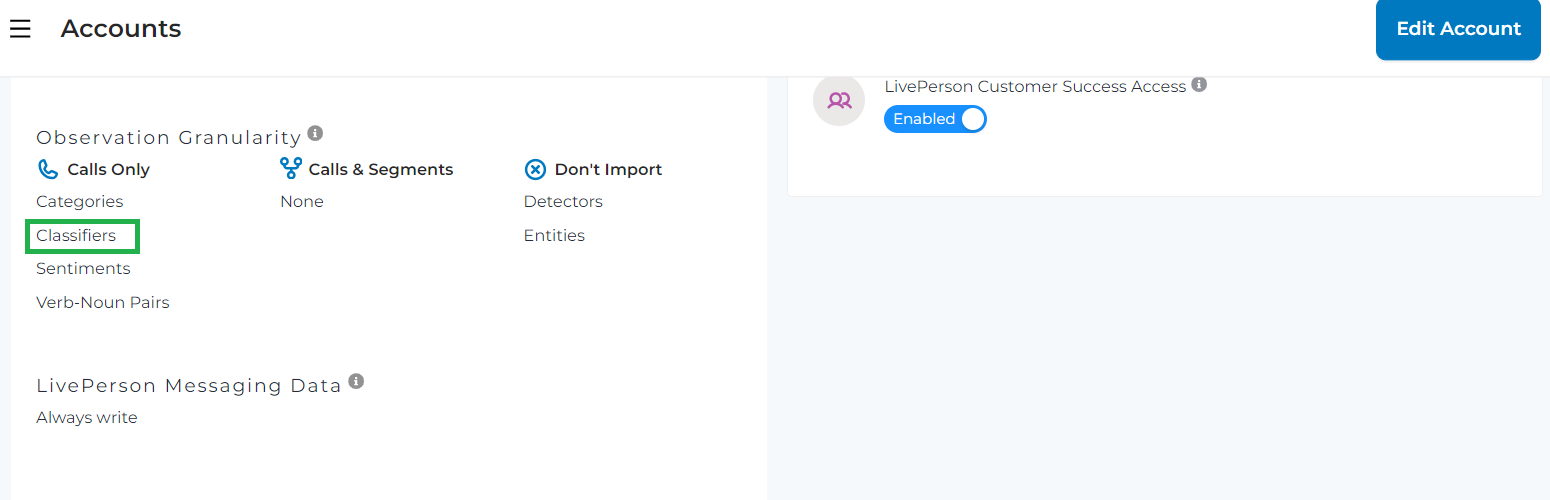
resolution model classifier switch
Since resolution models is implemented as a classifier, the results will be stored in CLASSIFIER_CONTENT_OBSERVATIONS and DM_ONTOLOGY_HIER table. The results will be on a conversation level (content level) as a classifier name ('Resolution Model') and its result ('yes', ‘no’, or null). Null values are populated if the model is not able to determine the outcome.
*The processing happens through VoiceBase Engine, a proprietary engine from VoiceBase - A LivePerson company.
Missing Something?
Check out our Developer Center for more in-depth documentation. Please share your documentation feedback with us using the feedback button. We'd be happy to hear from you.