Unsupervised NLU Model
Overview
Unsupervised NLU (Natural Language Understanding) model is designed to automatically analyze large textual datasets and discover topics and themes.It is a grouping of keywords that agent, bot or customer uses during chat or messaging transcripts. This can be used to help start creating a taxonomy.
How to add NLU model to dashboards:
- Choose dashboard for analysis and open it
- Click on the data stack icon on the left-hand side of your dashboard and then the 3 dots

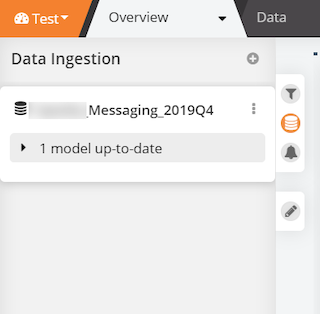
- Click on Edit

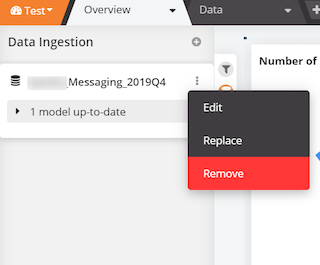
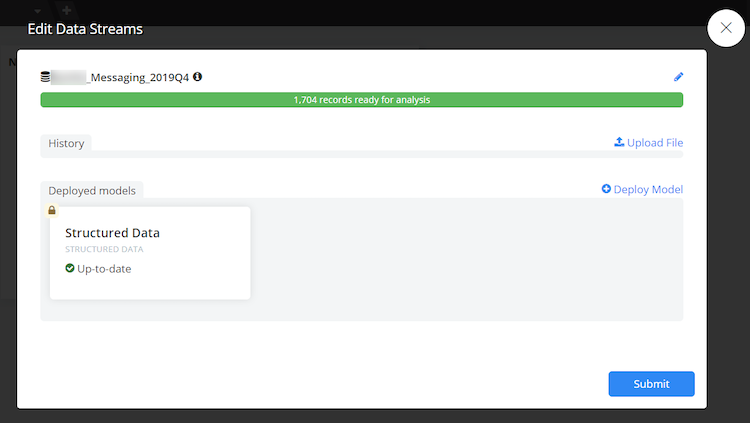
- Select Deploy New Model

- Choose Unsupervised NLU Model

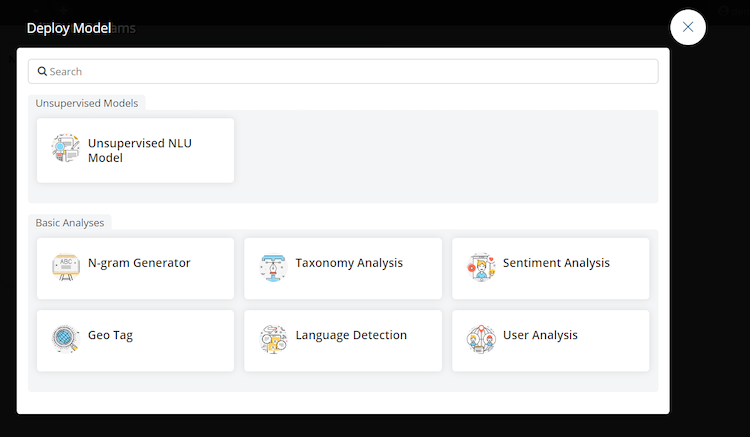
- Choose the type of verbatim (customer, agent, or bot) you would like to analyze from the list on the left side and then click on the plus sign and choose text

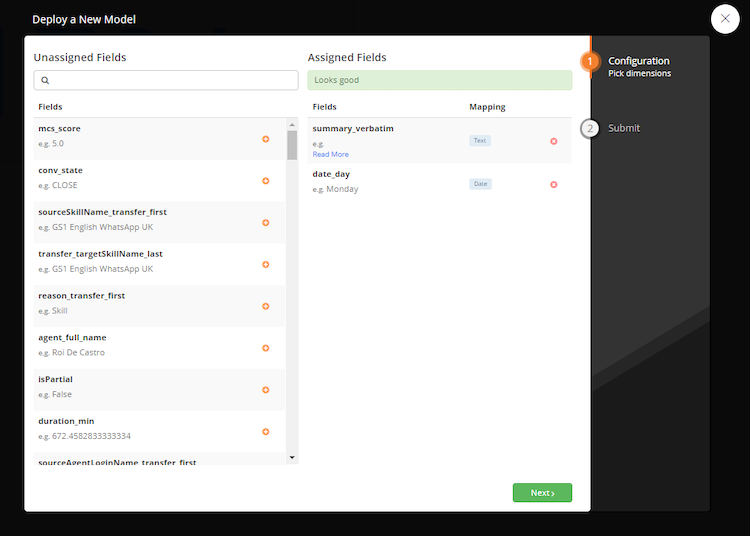
- Change the name of the Unsupervised NLU Model to include the type of verbatim you are analyzing and click Submit
- Choose Submit again
- Once the Unsupervised NLU Model starts processing, it will say “1 model processing”

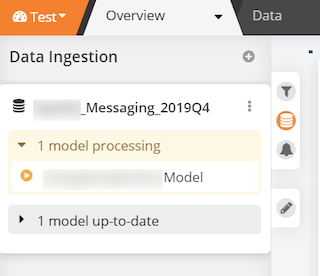
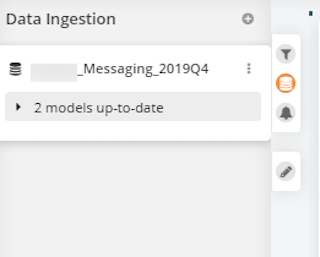
- Once processing is complete, it will say Models up-to-date on the left side

To create an Unsupervised NLU Model widget, go to the bottom right side and click the “+” sign to open the Widget editor
On the left side of the Widget editor, there will be a category for Unsupervised NLU Model and to see all topics, click on Topics

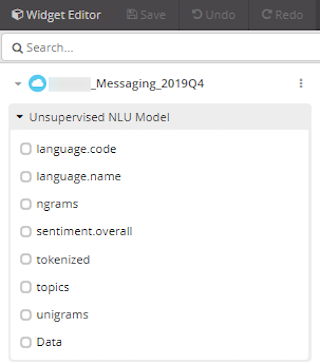
Definitions
- language.code - The two-letter language code of the detected language, e.g. en, fr, jp.
- language.name- The full name of the detected language, e.g. English, French, Japanese.
- ngrams - Sets of words (two by default) that appear together frequently in the corpus.
- sentiment.overall - The overall sentiment detected within the corpus, with values ranging from -5 to 5.
- tokenized - A list of every word detected in the corpus. This is trivial for languages that use spaces between words, but for languages in which there are no spaces between words and multi-character words are possible, each requires a custom tokenizer.
- topics- Clusters of similar themes or related terms within the corpus of text.
- unigrams - A textual array of single words within the data stream. Stratifyd calculates the total number of words and the number of unique values. Useful in a word cloud viewed with filters on average sentiment.
- Data - A table containing all of the original data from the data stream, plus all of the analyzed data from the model.
The default visual is the topic wheel which shows the most common word pairings that it was used during a chat/ conversation (this visualization can be created by selecting the ‘topic’ option under the Unsupervised NLU model in Widget editor)

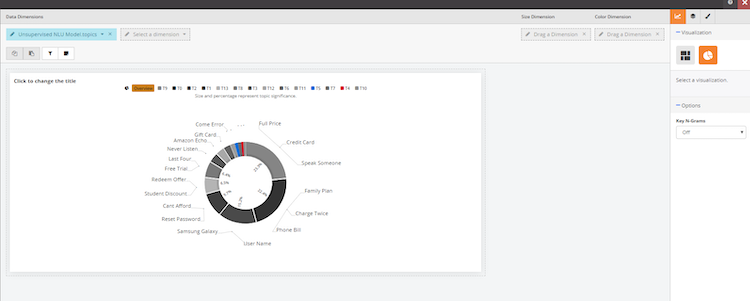
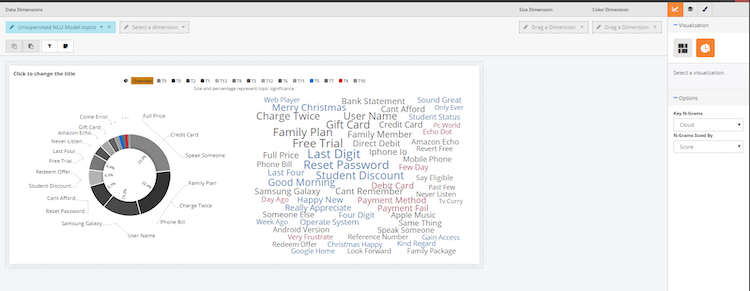
To add a word cloud or a list of words besides the topic wheel, go to the right side and look at the drop down menu under Key-N-Grams
Cloud View:

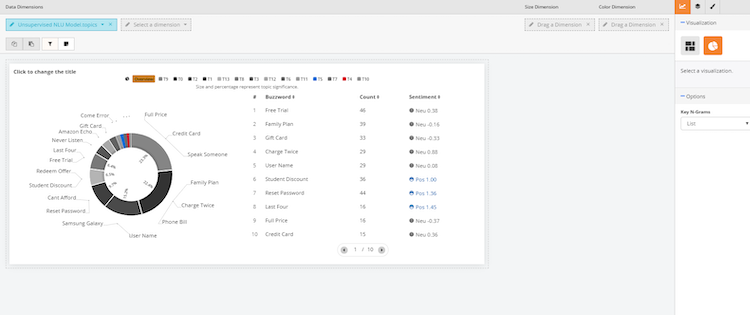
List View

Once a visual is decided, click Save and the widget will be added to the dashboard.
The Unsupervised NLU Model will show the most commonly used words that a customer, agent or bot used during a chat/ conversation. This can be used to identify the most common topics and themes and help tune or create a taxonomy.

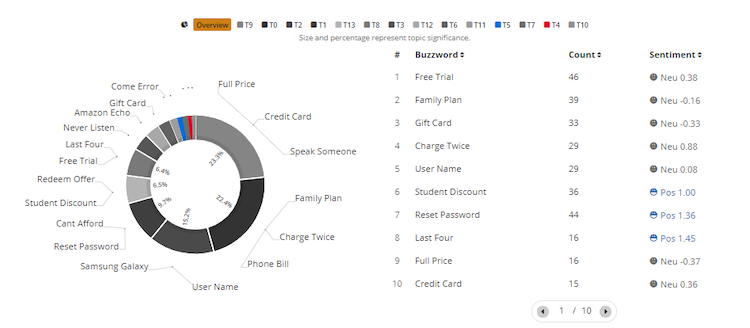
Buzzwords- word pairings that either customer/bot/agent used
Count- how many chats/conversations the buzzword was used'
Sentiment- score given for the buzzwords. Gray- neutral sentiment, blue- positive sentiment, red- negative sentiment
Users can analyze any of the topics by clicking on any topic. Once a filter is applied, the whole dashboard will reflect the latest filter.
Missing Something?
Check out our Developer Center for more in-depth documentation. Please share your documentation feedback with us using the feedback button. We'd be happy to hear from you.