LLM Gateway
Introduction
LivePerson’s Conversational Cloud includes a Large Language Model (LLM) Gateway that sits between our applications and the LLM service we use for Generative AI.

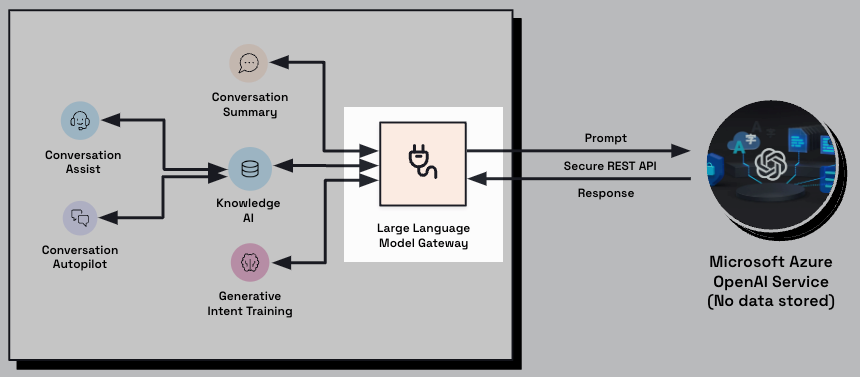
The primary job of the LLM Gateway is to pass requests to the LLM service and to receive responses in return. In this role, the gateway performs some post-processing that is both vital and useful.
Hallucination Detection post-processing
Hallucinations are situations where the LLM service generates incorrect or nonsensical responses due to not truly understanding the meaning of the input data. Typically, hallucinations happen when the LLM service relies too heavily on its language model and fails to effectively leverage the contextual data and brand knowledge that was provided to it. Since hallucinations by an LLM service can occur, detection is vital.
Currently, the Hallucination Detection post-processing service in our LLM Gateway takes the response received from the LLM service and checks it for hallucinations with respect to:
- URLs
- Phone numbers
- Email addresses
How the service works
The Hallucination Detection service checks the response from the LLM service to ensure that the URLs, phone numbers, and email addresses therein are valid. If a data point can’t be determined to be valid, the service asks the LLM service to rephrase the response without it.
Once the response is rephrased, if it still contains the given data point, the Hallucination Detection service discards the response and instead returns the following response to the LivePerson application that originally submitted the request:
I'm sorry, but I don't have that information available to me. Please contact our customer care team for further assistance.
Default configuration
By default, Hallucination Detection is turned on only for KnowledgeAI for all accounts. So, if you’re integrating with KnowledgeAI (in Conversation Assist or in a Conversation Builder bot), this feature is at work to ensure that answers enriched via Generative AI are safe with respect to hallucinations involving URLs, phone numbers, and email addresses.
URL post-processing
In Messaging contexts, URLs that are clickable are always handy and support an optimal experience for the end user. However, responses from the Large Language Model (LLM) service — which are formed via Generative AI — are always returned as plain text.
That’s where our URL post-processing service in the LLM Gateway comes in. It takes all the URLs in the response and wraps them in HTML tags, so they become active, clickable URLs.
Default configuration
By default, the URL post-processing service is on for KnowledgeAI for all accounts. To turn it off, contact your LivePerson representative.
Missing Something?
Check out our Developer Center for more in-depth documentation. Please share your documentation feedback with us using the feedback button. We'd be happy to hear from you.