Meaningful Automated Conversation Score (MACS)
What is MACS?
A Meaningful Automated Conversation Score (MACS) is a measure of the quality of a bot conversation.
LivePerson has found through research that consumer effort is a key determiner in how the consumer perceives the quality of a conversational experience. Given this, MACS is calculated by identifying and quantifying this using proprietary LivePerson AI logic. Issues within the bot conversation’s structure are detected and used to derive a score, for example:
- Did the bot understand the consumer’s question?
- Was the consumer stuck in an endless loop?
Here is a conversation with these example issues:

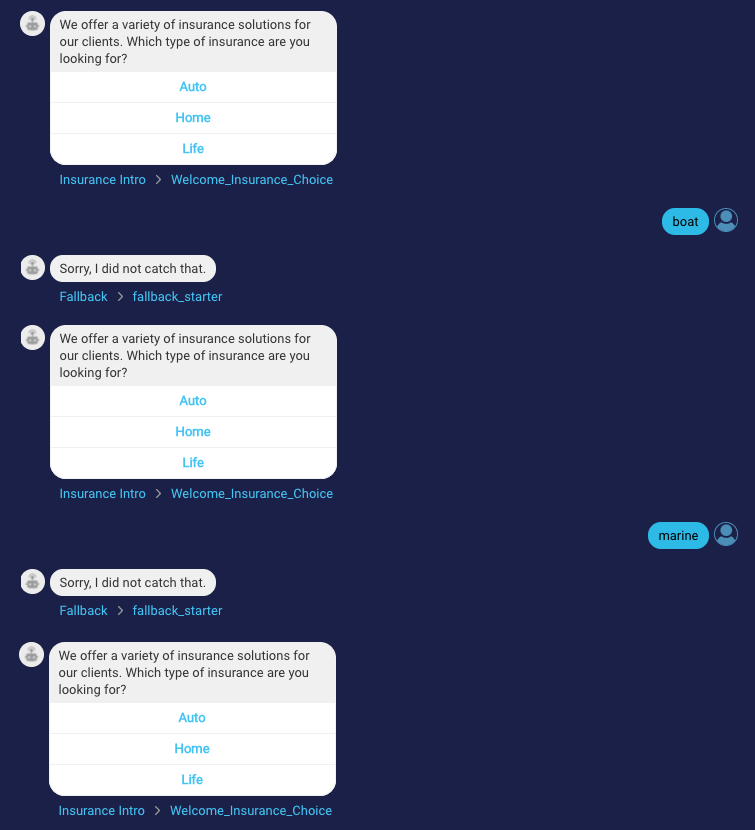
MACS is calculated for a bot conversation based on issues like those above. The conversation is classified with MACS 1, 2, or 3 where:
| Score | Icon | Description |
| 1 |  | A potentially below-average conversational experience was detected. Issues were found. The bot is unhelpful and needs immediate attention. |
| 2 |  | A potentially average conversational experience was detected. Some issues were found. The bot is still helpful but needs improvement. |
| 3 |  | A potentially good conversational experience was detected. Almost no issues were found. The bot still might need more tuning. |
To indicate overall bot performance, an average score (a floating number) is also calculated for each bot based on its conversations.

Scoring like this makes it fast and easy to understand how efficient and fluid a bot conversation was, and a bot’s performance overall. With this knowledge, you can take action and tune your low-performing bots for improved performance.
Constraints and caveats
- MACS scoring is only available for Messaging, not Chat.
- MACS scoring is only available for bots built-in Conversation Builder. For a third-party bot, “N/A” for “Not Applicable” is displayed as the MACS.
Why use MACS?
Other measures can inform you about the quality of conversations, but they do have some shortcomings when it comes to conversations with bots:
- Containment rates: Often a bot’s success or failure is measured by its containment rate, i.e., the number of conversations the bot contains without needing to involve a human. However, this measure isn’t always a good indicator. For example, if the consumer gets frustrated and abandons the conversation, the conversation is still counted as contained. Likewise, if the consumer is directed to call in, it is counted as contained.
- Post-conversation surveys (PCS), CSAT, and NPS: These measures:
- Are offered when the conversation is closed, but many bot conversations never reach that point.
- Have a low response rate, and when people do respond, they are not a representative sample. Typically, they are more extreme in their feelings about the bot.
- Don’t account for abandoned conversations, which is an important type of bot conversation to consider.
- Assess the entire conversation and don’t distinguish whether the agent or the bot caused the consumer’s satisfaction. They also don’t provide any indication of what caused the high or low score.
- Meaningful Connection Score (MCS): Research has revealed that humans don’t converse with bots as they do with humans: The number of words in each message decreases, and the use of emotional language is minimal. This means that LivePerson’s MCS, which uses natural language to measure the consumer’s sentiment as they message with an agent, isn’t a good indicator of the quality of a conversation with a bot.
MACS addresses all these shortcomings because it identifies and quantifies the issues that are found in the conversation’s structure to evaluate the conversation’s efficiency and fluidity. What’s more, MACS is available for all bot conversations while post-conversation surveys are not.
Benefits of MACS
MACS scoring makes it fast and easy to tune your bots for improved performance at scale. Using it, you can:
- Identify failed conversations: Easily find the conversations requiring high consumer effort.
- Review less, not more: Perform a targeted review of conversation transcripts, not a random review, to locate the bot areas that need improvement.
- Diagnose and tune quickly: Move directly from an issue in a transcript to the interaction in the bot flow, where you can make changes.
- Reduce negative consumer feedback: With MACS, you’re provided with AI-generated opportunities to improve your bots, reducing potential negative consumer feedback.
How is MACS calculated?
There are two AI-based models responsible for MACS:
- A model that predicts what issues are present in the conversation
- A model that estimates a conversation quality score
Both of these models were “trained” by having human experts manually annotate thousands of conversations. Using these models, each bot conversation that is closed is classified with MACS 1, 2, or 3 where:
| Score | Icon | Description |
| 1 | | A potentially below-average conversational experience was detected. Issues were found. The bot is unhelpful and needs immediate attention. |
| 2 | | A potentially average conversational experience was detected. Some issues were found. The bot is still helpful but needs improvement. |
| 3 | | A potentially good conversational experience was detected. Almost no issues were found. The bot still might need more tuning. |
The score is calculated based on the presence of issues in the conversation, along with a host of other metadata associated with the conversation. The table below describes the issue types used to derive MACS and provides solutions for fixing them.
| Issue type | Description | Possible fixes |
| Stuck in a loop | The consumer is stuck in an unintentional loop. | Improve the dialog/conversation flow Escalate to agent |
| Ignored consumer question | The bot doesn’t acknowledge the consumer's query and instead forces the consumer through a dialog flow. | Add intent detection (NLU) Add menu options |
| Doesn't understand | The bot fails to understand the consumer's intent and is not offering to repair the conversation. | Improve poor-performing intents Add intents Move to a menu-based approach |
| Poor transfer experience | The bot transfers the consumer to an agent, but this either leaves the consumer hanging or abruptly ends the conversation. The bot might also fail to tell the consumer early enough in the conversation that there are no agents available at that hour. | Give a warning early in the conversation that agents are near capacity Check if agents are available before declaring the conversation will be escalated |
The MACS model doesn't detect where an issue occurred in a conversation; it detects whether or not it occurred somewhere in the conversation. Within the Bot Analytics application, you can:
- See which issues occurred in a conversation
- Provide feedback on both the conversation’s MACS and the identified issues
Accuracy of MACS
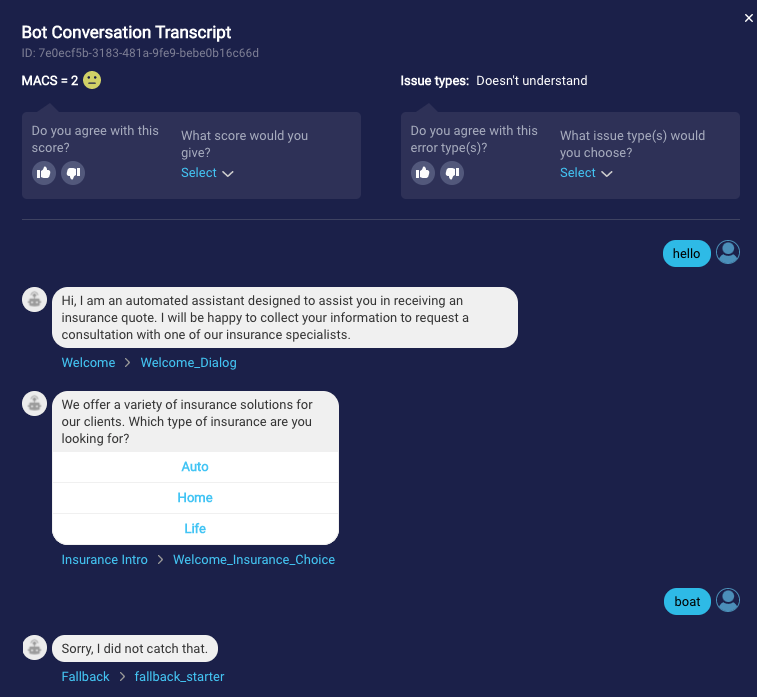
While MACS has a strong agreement with human judgments of conversation quality (a correlation of .61), you can expect the algorithm to make some classification mistakes from time to time. The strength of MACS comes from looking at the scores in aggregate, where one aspect is in common (e.g., the same issue is detected, or the conversations included a specific interaction or intent).
On the Bot Conversation Transcript page, you’ll find a quick and easy feedback feature. We encourage you to send us your feedback on a conversation’s MACS and identified issues. This helps us to tune and improve the MACS AI logic.

Using MACS in Bot Analytics
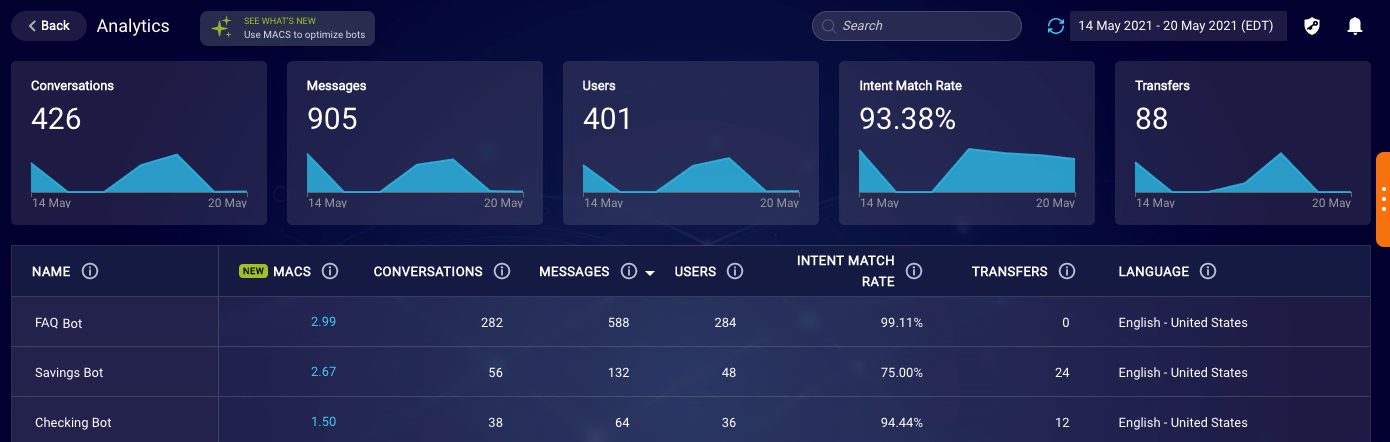
Within the Conversational AI suite’s Bot Analytics application, you can review in-depth the MACS data for your bots. MACS data helps you to quickly identify underperforming bots, find their issues, and move to bot/intent tuning, so you can optimize performance. For more on this, see here.
Missing Something?
Check out our Developer Center for more in-depth documentation. Please share your documentation feedback with us using the feedback button. We'd be happy to hear from you.